# Web3-AIトラック全景レポート:技術ロジック、シーンアプリケーションとトッププロジェクトのデプス分析AIのナラティブが進展する中、この分野への関心が高まっています。本記事では、Web3-AI分野の技術的論理、応用シーン、代表的なプロジェクトを深く分析し、この分野の全体像と発展のトレンドを包括的に呈示します。## I. Web3-AI:テクニカルロジックと新興市場の機会分析### 1.1 Web3とAIの融合ロジック: Web3-AIトラックをどのように定義するか過去一年間、AIナarrティブはWeb3業界で異常に人気を博し、AIプロジェクトが雨後の筍のように次々と現れました。多くのプロジェクトがAI技術を取り入れていますが、一部のプロジェクトはその製品の一部でのみAIを使用しており、基盤となるトークンエコノミクスとAI製品には実質的な関連がないため、このようなプロジェクトは本稿でのWeb3-AIプロジェクトの議論には含まれません。この記事の焦点は、ブロックチェーンを使用して生産関係の問題を解決し、AIが生産力の問題を解決するプロジェクトにあります。これらのプロジェクトは自らAI製品を提供し、同時にWeb3経済モデルに基づいて生産関係のツールとして機能し、両者は相互に補完し合います。このようなプロジェクトをWeb3-AIセクターに分類します。読者がWeb3-AIセクターをより良く理解できるように、この記事ではAIの開発プロセスや課題、Web3とAIの結合がどのように問題を完璧に解決し、新しいアプリケーションシーンを創造するのかを紹介します。### 1.2 AIの開発プロセスと課題:データ収集からモデル推論までAI技術はコンピュータが人間の知能を模倣、拡張、強化することを可能にする技術です。それにより、コンピュータは言語翻訳、画像分類、顔認識、自動運転などのさまざまな複雑なタスクを実行できるようになり、AIは私たちの生活や働き方を変えています。人工知能モデルの開発プロセスには通常、以下のいくつかの重要なステップが含まれます: データ収集とデータ前処理、モデル選択とチューニング、モデルのトレーニングと推論。簡単な例を挙げると、猫と犬の画像を分類するモデルを開発するには、次のことが必要です:1. データ収集とデータ前処理: 猫と犬の画像データセットを収集します。公開データセットを使用するか、実際のデータを自分で収集できます。そして、各画像にカテゴリ(猫または犬)のラベルを付け、ラベルが正確であることを確認します。画像をモデルが認識できる形式に変換し、データセットをトレーニングセット、検証セット、テストセットに分割します。2. モデル選択と調整: 適切なモデルを選択します。例えば、畳み込みニューラルネットワーク(CNN)は、画像分類タスクに適しています。異なるニーズに応じてモデルのパラメータやアーキテクチャを調整します。一般的に、モデルのネットワーク階層はAIタスクの複雑さに応じて調整できます。この簡単な分類の例では、浅いネットワーク階層で十分かもしれません。3. モデルのトレーニング: GPU、TPU、または高性能計算クラスターを使用してモデルをトレーニングできます。トレーニング時間はモデルの複雑さと計算能力の影響を受けます。4. モデル推論:モデルが訓練されたファイルは通常モデルの重みと呼ばれ、推論プロセスは既に訓練されたモデルを使用して新しいデータに対して予測または分類を行うプロセスを指します。このプロセスではテストセットまたは新しいデータを使用してモデルの分類効果をテストすることができ、通常は精度、再現率、F1スコアなどの指標を用いてモデルの有効性を評価します。しかし、中央集権的なAI開発プロセスには以下のシナリオでいくつかの問題があります:ユーザープライバシー:中央集権的なシーンでは、AIの開発プロセスは通常不透明です。ユーザーデータは知らないうちに盗まれ、AIのトレーニングに使用される可能性があります。データソース取得:小規模チームまたは個人が特定の分野のデータ(、例えば医療データ)を取得する際には、データがオープンソースでない制約に直面する可能性があります。モデル選択とチューニング: 小規模なチームにとって、特定の分野のモデルリソースを取得したり、モデルのチューニングに多大なコストをかけたりすることは困難です。算力取得: 個人開発者や小規模チームにとって、高額なGPU購入費用やクラウド算力レンタル費用は、かなりの経済的負担となる可能性があります。AI資産収入:データラベリング作業者はしばしばその労力に見合った収入を得ることができず、AI開発者の研究成果も需要のあるバイヤーとマッチすることが困難です。中心化AIシーンで存在する課題はWeb3との結びつきによって解決できる。Web3は新しい生産関係の一形態として、自然に新しい生産力を代表するAIに適応し、技術と生産能力の同時進歩を促進する。### 1.3 Web3とAIのシナジー:役割の変化と革新的なアプリケーションWeb3とAIの融合はユーザーの主権を強化し、ユーザーにオープンなAI協力プラットフォームを提供します。これにより、ユーザーはWeb2時代のAIユーザーから参加者に変わり、誰もが所有できるAIを作成します。同時に、Web3の世界とAI技術の融合は、さらなる革新的なアプリケーションシーンやプレイスタイルを生み出すことができます。Web3技術に基づき、AIの開発と応用は新しい協力経済システムを迎えることになります。人々のデータプライバシーは保障され、データクラウドソーシングモデルがAIモデルの進歩を促進し、多くのオープンソースのAIリソースがユーザーに利用可能になります。共有された算力は低コストで取得できます。分散型の協力クラウドソーシングメカニズムとオープンなAI市場を活用することで、公平な収入分配システムを実現し、より多くの人々がAI技術の進歩を促進することを奨励します。Web3のシーンでは、AIが複数のトラックで積極的な影響を与えることができます。例えば、AIモデルはスマートコントラクトに統合され、マーケット分析、安全検出、ソーシャルクラスタリングなど、さまざまなアプリケーションシナリオで作業効率を向上させることができます。生成的AIは、ユーザーに「アーティスト」の役割を体験させるだけでなく、AI技術を使用して自分のNFTを作成したり、GameFiで多様なゲームシナリオや面白いインタラクション体験を創出したりすることができます。豊富なインフラはスムーズな開発体験を提供し、AI専門家でもAIの分野に参入したい初心者でも、この世界で適切な入り口を見つけることができます。## 二、Web3-AIエコシステムプロジェクトの地図とアーキテクチャの解読私たちは主にWeb3-AIトラックの41のプロジェクトを研究し、これらのプロジェクトを異なるレベルに分類しました。各レベルの分類ロジックは以下の図に示されており、インフラストラクチャーレベル、中間レベル、アプリケーションレベルが含まれ、各レベルはさらに異なるセクションに分かれています。次の章では、代表的なプロジェクトのデプス解析を行います。インフラストラクチャ層は、AIライフサイクル全体の運用をサポートする計算リソースと技術アーキテクチャをカバーし、中間層はインフラストラクチャとアプリケーションを接続するデータ管理、モデル開発、および検証推論サービスを含み、アプリケーション層はユーザーに直接向けたさまざまなアプリケーションとソリューションに焦点を当てています。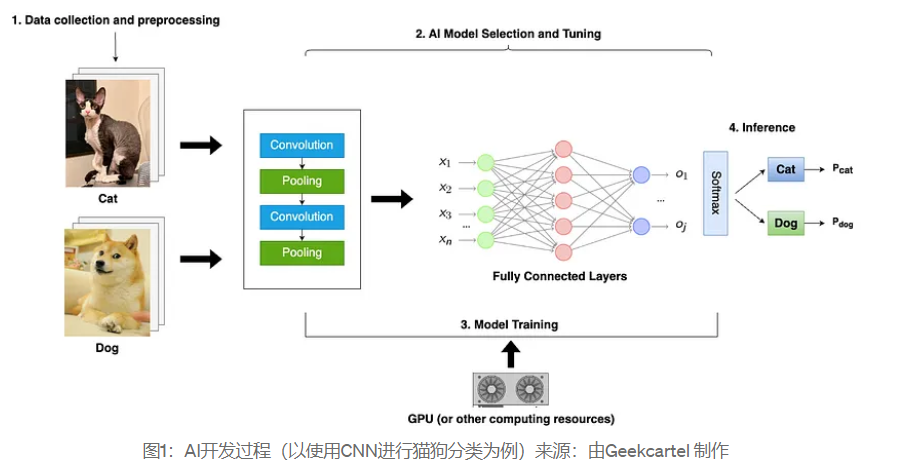インフラ層:インフラ層はAIライフサイクルの基盤であり、この記事ではコンピューティングパワー、AIチェーン、開発プラットフォームをインフラ層に分類しています。これらのインフラのサポートによってこそ、AIモデルのトレーニングと推論が実現し、強力で実用的なAIアプリケーションがユーザーに提供されます。- 分散型コンピューティングネットワーク: AIモデルのトレーニングに分散型の計算能力を提供し、高効率かつ経済的な計算リソースの利用を確保します。一部のプロジェクトは分散型の計算能力市場を提供し、ユーザーは低コストで計算能力をレンタルしたり、計算能力を共有して収益を得ることができます。代表的なプロジェクトにはIO.NETやHyperbolicがあります。さらに、一部のプロジェクトは新しい遊び方を派生させ、Compute Labsのように、トークン化プロトコルを提案しています。ユーザーはGPU実体を代表するNFTを購入することで、異なる方法で計算能力のレンタルに参加し、収益を得ることができます。- AIチェーン: ブロックチェーンをAIライフサイクルの基盤として利用し、オンチェーンとオフチェーンのAIリソースのシームレスな相互作用を実現し、業界エコシステムの発展を促進します。チェーン上の分散型AI市場では、データ、モデル、エージェントなどのAI資産を取引でき、AI開発フレームワークと関連する開発ツールを提供します。代表的なプロジェクトにはSahara AIがあります。AIチェーンはまた、異なる分野のAI技術の進歩を促進することができます。例えば、Bittensorは革新的なサブネットインセンティブメカニズムを通じて、異なるAIタイプのサブネット競争を促進しています。- 開発プラットフォーム: 一部のプロジェクトはAIエージェント開発プラットフォームを提供しており、Fetch.aiやChainMLなどのようにAIエージェントの取引も実現できます。ワンストップのツールが開発者がAIモデルをより便利に作成、訓練、展開するのを助け、代表的なプロジェクトはNimbleです。これらのインフラストラクチャは、Web3エコシステムにおけるAI技術の広範な応用を促進しています。中間:このレイヤーはAIデータ、モデル、推論および検証に関連しており、Web3技術を使用することでより高い作業効率を実現できます。- データ:データの質と量はモデルのトレーニング効果に影響を与える重要な要素です。Web3の世界では、クラウドソーシングデータや協力的なデータ処理を通じて、リソースの利用を最適化し、データコストを削減できます。ユーザーはデータの自主権を持ち、プライバシー保護の下で自分のデータを販売することができ、不正な業者にデータを盗まれ、高額な利益を得られるのを避けることができます。データ需要者にとって、これらのプラットフォームは広範な選択肢と非常に低いコストを提供します。代表的なプロジェクトとして、Grassはユーザーの帯域幅を利用してWebデータを取得し、xDataはユーザーフレンドリーなプラグインを通じてメディア情報を収集し、ユーザーがツイート情報をアップロードすることをサポートしています。さらに、一部のプラットフォームでは、分野の専門家や一般ユーザーがデータ前処理タスクを実行できるようにしています。これには、画像ラベリングやデータ分類などが含まれ、これらのタスクは専門知識を必要とする金融や法律関連のデータ処理が求められる場合があります。ユーザーはスキルをトークン化することで、データ前処理の協力的なクラウドソーシングを実現できます。Sahara AIのようなAIマーケットプレイスは、異なる分野のデータタスクを持ち、複数の分野のデータシーンをカバーできます。一方、AIT Protocolは人間と機械が協力してデータにラベリングを行います。- モデル:以前に述べたAI開発プロセスでは、異なるタイプのニーズに適したモデルをマッチングする必要があります。画像タスクでよく使用されるモデルにはCNNやGANがあり、物体検出タスクにはYoloシリーズを選択できます。テキスト系のタスクではRNNやTransformerなどのモデルが一般的です。もちろん、特定のまたは汎用の大きなモデルもあります。異なる複雑さのタスクに必要なモデルのデプスも異なり、時にはモデルの調整が必要です。いくつかのプロジェクトは、ユーザーが異なるタイプのモデルを提供したり、クラウドソーシングで協力してモデルをトレーニングすることをサポートしています。たとえば、Sentientはモジュラー設計を通じて、ユーザーが信頼できるモデルデータをストレージ層や配信層に置いてモデルの最適化を行えるようにしています。Sahara AIが提供する開発ツールは、先進的なAIアルゴリズムと計算フレームワークを内蔵しており、協力トレーニングの能力を持っています。- 推論と検証: モデルがトレーニングされた後、モデルの重みファイルが生成され、分類、予測、またはその他の特定のタスクを直接実行するために使用できます。このプロセスは推論と呼ばれます。推論プロセスには通常、推論モデルの出所が正しいか、悪意のある行動がないかを検証するための検証メカニズムが伴います。Web3の推論は通常、スマートコントラクトに統合され、モデルを呼び出して推論を行います。一般的な検証方法にはZKML、OPML、TEEなどの技術が含まれます。代表的なプロジェクトとしては、ORAチェーン上のAIオラクル(OAO)があり、AIオラクルの検証可能なレイヤーとしてOPMLを導入しています。ORAの公式サイトでは、ZKMLとopp/ai(ZKMLとOPML)の統合に関する研究についても言及されています。アプリケーション層:この層は主にユーザー向けのアプリケーションであり、AIとWeb3を組み合わせて、より多くの興味深い革新的なプレイを生み出します。本記事では、AIGC(AI生成コンテンツ)、AIエージェント、データ分析のいくつかのセクターのプロジェクトを整理します。- AIGC: AIGCを通じてWeb3のNFT、ゲームなどの領域に拡張できます。ユーザーはPrompt(ユーザーが提供するプロンプト)を直接使用して、テキスト、画像、音声を生成することができ、さらには自分の好みに基づいてゲーム内でカスタマイズされたプレイスタイルを生成することも可能です。NFTプロジェクトであるNFPromptでは、ユーザーはAIを使用してNFTを生成し、市場で取引することができます。ゲームであるSleeplessでは、ユーザーは対話を通じて仮想のパートナーの性格を形成し、自分の好みに合わせることができます;- AIエージェント: 自主的にタスクを実行し、意思決定を行うことができる人工知能システムを指します。AIエージェントは通常、感知、推論、学習、行動の能力を備えており、さまざまな環境で複雑なタスクを実行できます。一般的なAIエージェントには、言語翻訳、言語学習、画像からテキストへの変換などがあり、Web3のシーンでは取引ロボットの生成、ミームの生成、オンチェーンのセキュリティ検査などが可能です。MyShellはAIエージェントプラットフォームとして、教育学習、バーチャルパートナー、取引エージェントなど、さまざまなタイプのエージェントを提供し、ユーザーフレンドリーなエージェント開発ツールを提供しており、コード不要で自分だけのエージェントを構築できます。- データ分析: AI技術と関連分野のデータベースを取り入れることによって、データの分析、判断、予測などを実現します。Web3では、市場データやスマートマネーの動向を分析することで、ユーザーの投資判断をサポートできます。トークン予測もWeb3のユニークなアプリケーションシーンであり、代表的なプロジェクトとしてOceanがあり、公式はトークン予測の長期設定を行っています。
Web3-AIの全景:技術融合の論理、アプリケーションシーンとトッププロジェクトの分析
Web3-AIトラック全景レポート:技術ロジック、シーンアプリケーションとトッププロジェクトのデプス分析
AIのナラティブが進展する中、この分野への関心が高まっています。本記事では、Web3-AI分野の技術的論理、応用シーン、代表的なプロジェクトを深く分析し、この分野の全体像と発展のトレンドを包括的に呈示します。
I. Web3-AI:テクニカルロジックと新興市場の機会分析
1.1 Web3とAIの融合ロジック: Web3-AIトラックをどのように定義するか
過去一年間、AIナarrティブはWeb3業界で異常に人気を博し、AIプロジェクトが雨後の筍のように次々と現れました。多くのプロジェクトがAI技術を取り入れていますが、一部のプロジェクトはその製品の一部でのみAIを使用しており、基盤となるトークンエコノミクスとAI製品には実質的な関連がないため、このようなプロジェクトは本稿でのWeb3-AIプロジェクトの議論には含まれません。
この記事の焦点は、ブロックチェーンを使用して生産関係の問題を解決し、AIが生産力の問題を解決するプロジェクトにあります。これらのプロジェクトは自らAI製品を提供し、同時にWeb3経済モデルに基づいて生産関係のツールとして機能し、両者は相互に補完し合います。このようなプロジェクトをWeb3-AIセクターに分類します。読者がWeb3-AIセクターをより良く理解できるように、この記事ではAIの開発プロセスや課題、Web3とAIの結合がどのように問題を完璧に解決し、新しいアプリケーションシーンを創造するのかを紹介します。
1.2 AIの開発プロセスと課題:データ収集からモデル推論まで
AI技術はコンピュータが人間の知能を模倣、拡張、強化することを可能にする技術です。それにより、コンピュータは言語翻訳、画像分類、顔認識、自動運転などのさまざまな複雑なタスクを実行できるようになり、AIは私たちの生活や働き方を変えています。
人工知能モデルの開発プロセスには通常、以下のいくつかの重要なステップが含まれます: データ収集とデータ前処理、モデル選択とチューニング、モデルのトレーニングと推論。簡単な例を挙げると、猫と犬の画像を分類するモデルを開発するには、次のことが必要です:
データ収集とデータ前処理: 猫と犬の画像データセットを収集します。公開データセットを使用するか、実際のデータを自分で収集できます。そして、各画像にカテゴリ(猫または犬)のラベルを付け、ラベルが正確であることを確認します。画像をモデルが認識できる形式に変換し、データセットをトレーニングセット、検証セット、テストセットに分割します。
モデル選択と調整: 適切なモデルを選択します。例えば、畳み込みニューラルネットワーク(CNN)は、画像分類タスクに適しています。異なるニーズに応じてモデルのパラメータやアーキテクチャを調整します。一般的に、モデルのネットワーク階層はAIタスクの複雑さに応じて調整できます。この簡単な分類の例では、浅いネットワーク階層で十分かもしれません。
モデルのトレーニング: GPU、TPU、または高性能計算クラスターを使用してモデルをトレーニングできます。トレーニング時間はモデルの複雑さと計算能力の影響を受けます。
モデル推論:モデルが訓練されたファイルは通常モデルの重みと呼ばれ、推論プロセスは既に訓練されたモデルを使用して新しいデータに対して予測または分類を行うプロセスを指します。このプロセスではテストセットまたは新しいデータを使用してモデルの分類効果をテストすることができ、通常は精度、再現率、F1スコアなどの指標を用いてモデルの有効性を評価します。
しかし、中央集権的なAI開発プロセスには以下のシナリオでいくつかの問題があります:
ユーザープライバシー:中央集権的なシーンでは、AIの開発プロセスは通常不透明です。ユーザーデータは知らないうちに盗まれ、AIのトレーニングに使用される可能性があります。
データソース取得:小規模チームまたは個人が特定の分野のデータ(、例えば医療データ)を取得する際には、データがオープンソースでない制約に直面する可能性があります。
モデル選択とチューニング: 小規模なチームにとって、特定の分野のモデルリソースを取得したり、モデルのチューニングに多大なコストをかけたりすることは困難です。
算力取得: 個人開発者や小規模チームにとって、高額なGPU購入費用やクラウド算力レンタル費用は、かなりの経済的負担となる可能性があります。
AI資産収入:データラベリング作業者はしばしばその労力に見合った収入を得ることができず、AI開発者の研究成果も需要のあるバイヤーとマッチすることが困難です。
中心化AIシーンで存在する課題はWeb3との結びつきによって解決できる。Web3は新しい生産関係の一形態として、自然に新しい生産力を代表するAIに適応し、技術と生産能力の同時進歩を促進する。
1.3 Web3とAIのシナジー:役割の変化と革新的なアプリケーション
Web3とAIの融合はユーザーの主権を強化し、ユーザーにオープンなAI協力プラットフォームを提供します。これにより、ユーザーはWeb2時代のAIユーザーから参加者に変わり、誰もが所有できるAIを作成します。同時に、Web3の世界とAI技術の融合は、さらなる革新的なアプリケーションシーンやプレイスタイルを生み出すことができます。
Web3技術に基づき、AIの開発と応用は新しい協力経済システムを迎えることになります。人々のデータプライバシーは保障され、データクラウドソーシングモデルがAIモデルの進歩を促進し、多くのオープンソースのAIリソースがユーザーに利用可能になります。共有された算力は低コストで取得できます。分散型の協力クラウドソーシングメカニズムとオープンなAI市場を活用することで、公平な収入分配システムを実現し、より多くの人々がAI技術の進歩を促進することを奨励します。
Web3のシーンでは、AIが複数のトラックで積極的な影響を与えることができます。例えば、AIモデルはスマートコントラクトに統合され、マーケット分析、安全検出、ソーシャルクラスタリングなど、さまざまなアプリケーションシナリオで作業効率を向上させることができます。生成的AIは、ユーザーに「アーティスト」の役割を体験させるだけでなく、AI技術を使用して自分のNFTを作成したり、GameFiで多様なゲームシナリオや面白いインタラクション体験を創出したりすることができます。豊富なインフラはスムーズな開発体験を提供し、AI専門家でもAIの分野に参入したい初心者でも、この世界で適切な入り口を見つけることができます。
二、Web3-AIエコシステムプロジェクトの地図とアーキテクチャの解読
私たちは主にWeb3-AIトラックの41のプロジェクトを研究し、これらのプロジェクトを異なるレベルに分類しました。各レベルの分類ロジックは以下の図に示されており、インフラストラクチャーレベル、中間レベル、アプリケーションレベルが含まれ、各レベルはさらに異なるセクションに分かれています。次の章では、代表的なプロジェクトのデプス解析を行います。
インフラストラクチャ層は、AIライフサイクル全体の運用をサポートする計算リソースと技術アーキテクチャをカバーし、中間層はインフラストラクチャとアプリケーションを接続するデータ管理、モデル開発、および検証推論サービスを含み、アプリケーション層はユーザーに直接向けたさまざまなアプリケーションとソリューションに焦点を当てています。
インフラ層:
インフラ層はAIライフサイクルの基盤であり、この記事ではコンピューティングパワー、AIチェーン、開発プラットフォームをインフラ層に分類しています。これらのインフラのサポートによってこそ、AIモデルのトレーニングと推論が実現し、強力で実用的なAIアプリケーションがユーザーに提供されます。
分散型コンピューティングネットワーク: AIモデルのトレーニングに分散型の計算能力を提供し、高効率かつ経済的な計算リソースの利用を確保します。一部のプロジェクトは分散型の計算能力市場を提供し、ユーザーは低コストで計算能力をレンタルしたり、計算能力を共有して収益を得ることができます。代表的なプロジェクトにはIO.NETやHyperbolicがあります。さらに、一部のプロジェクトは新しい遊び方を派生させ、Compute Labsのように、トークン化プロトコルを提案しています。ユーザーはGPU実体を代表するNFTを購入することで、異なる方法で計算能力のレンタルに参加し、収益を得ることができます。
AIチェーン: ブロックチェーンをAIライフサイクルの基盤として利用し、オンチェーンとオフチェーンのAIリソースのシームレスな相互作用を実現し、業界エコシステムの発展を促進します。チェーン上の分散型AI市場では、データ、モデル、エージェントなどのAI資産を取引でき、AI開発フレームワークと関連する開発ツールを提供します。代表的なプロジェクトにはSahara AIがあります。AIチェーンはまた、異なる分野のAI技術の進歩を促進することができます。例えば、Bittensorは革新的なサブネットインセンティブメカニズムを通じて、異なるAIタイプのサブネット競争を促進しています。
開発プラットフォーム: 一部のプロジェクトはAIエージェント開発プラットフォームを提供しており、Fetch.aiやChainMLなどのようにAIエージェントの取引も実現できます。ワンストップのツールが開発者がAIモデルをより便利に作成、訓練、展開するのを助け、代表的なプロジェクトはNimbleです。これらのインフラストラクチャは、Web3エコシステムにおけるAI技術の広範な応用を促進しています。
中間:
このレイヤーはAIデータ、モデル、推論および検証に関連しており、Web3技術を使用することでより高い作業効率を実現できます。
さらに、一部のプラットフォームでは、分野の専門家や一般ユーザーがデータ前処理タスクを実行できるようにしています。これには、画像ラベリングやデータ分類などが含まれ、これらのタスクは専門知識を必要とする金融や法律関連のデータ処理が求められる場合があります。ユーザーはスキルをトークン化することで、データ前処理の協力的なクラウドソーシングを実現できます。Sahara AIのようなAIマーケットプレイスは、異なる分野のデータタスクを持ち、複数の分野のデータシーンをカバーできます。一方、AIT Protocolは人間と機械が協力してデータにラベリングを行います。
いくつかのプロジェクトは、ユーザーが異なるタイプのモデルを提供したり、クラウドソーシングで協力してモデルをトレーニングすることをサポートしています。たとえば、Sentientはモジュラー設計を通じて、ユーザーが信頼できるモデルデータをストレージ層や配信層に置いてモデルの最適化を行えるようにしています。Sahara AIが提供する開発ツールは、先進的なAIアルゴリズムと計算フレームワークを内蔵しており、協力トレーニングの能力を持っています。
アプリケーション層:
この層は主にユーザー向けのアプリケーションであり、AIとWeb3を組み合わせて、より多くの興味深い革新的なプレイを生み出します。本記事では、AIGC(AI生成コンテンツ)、AIエージェント、データ分析のいくつかのセクターのプロジェクトを整理します。
AIGC: AIGCを通じてWeb3のNFT、ゲームなどの領域に拡張できます。ユーザーはPrompt(ユーザーが提供するプロンプト)を直接使用して、テキスト、画像、音声を生成することができ、さらには自分の好みに基づいてゲーム内でカスタマイズされたプレイスタイルを生成することも可能です。NFTプロジェクトであるNFPromptでは、ユーザーはAIを使用してNFTを生成し、市場で取引することができます。ゲームであるSleeplessでは、ユーザーは対話を通じて仮想のパートナーの性格を形成し、自分の好みに合わせることができます;
AIエージェント: 自主的にタスクを実行し、意思決定を行うことができる人工知能システムを指します。AIエージェントは通常、感知、推論、学習、行動の能力を備えており、さまざまな環境で複雑なタスクを実行できます。一般的なAIエージェントには、言語翻訳、言語学習、画像からテキストへの変換などがあり、Web3のシーンでは取引ロボットの生成、ミームの生成、オンチェーンのセキュリティ検査などが可能です。MyShellはAIエージェントプラットフォームとして、教育学習、バーチャルパートナー、取引エージェントなど、さまざまなタイプのエージェントを提供し、ユーザーフレンドリーなエージェント開発ツールを提供しており、コード不要で自分だけのエージェントを構築できます。
データ分析: AI技術と関連分野のデータベースを取り入れることによって、データの分析、判断、予測などを実現します。Web3では、市場データやスマートマネーの動向を分析することで、ユーザーの投資判断をサポートできます。トークン予測もWeb3のユニークなアプリケーションシーンであり、代表的なプロジェクトとしてOceanがあり、公式はトークン予測の長期設定を行っています。