zkPyTorch: Trazendo Prova de conhecimento zero para Inferência PyTorch para uma IA verdadeiramente confiável
À medida que a inteligência artificial (IA) está a ser cada vez mais implementada em áreas-chave como a saúde, as finanças e a condução autónoma, garantir a fiabilidade, a transparência e a segurança do processo de inferência de aprendizagem automática (ML) está a tornar-se mais importante do que nunca.
No entanto, os serviços tradicionais de aprendizagem automática muitas vezes operam como uma “caixa preta”, onde os utilizadores só conseguem ver os resultados e têm dificuldade em verificar o processo. Esta falta de transparência torna os serviços de modelos vulneráveis a riscos:
O modelo foi roubado,
O resultado da inferência foi maliciosamente adulterado,
Os dados dos usuários estão em risco de violações de privacidade.
ZKML (Aprendizagem de Máquina zk-SNARKs) fornece uma nova solução criptográfica para este desafio. Baseia-se na tecnologia zk-SNARKs, concedendo aos modelos de aprendizagem de máquina a capacidade de serem criptografados de forma verificável: provando que um cálculo foi executado corretamente sem revelar qualquer informação sensível.
Em outras palavras, as Provas de Conhecimento Zero permitem que os prestadores de serviços provem aos usuários que:
"Os resultados da inferência que você obteve foram, de fato, gerados pelo modelo treinado que executei — mas não divulgarei nenhum parâmetro do modelo."
Isto significa que os utilizadores podem confiar na autenticidade dos resultados da inferência, enquanto a estrutura e os parâmetros do modelo (que são frequentemente ativos de alto valor) permanecem privados.
zkPyTorch:
A Polyhedra Network lançou o zkPyTorch, um compilador revolucionário especialmente projetado para aprendizado de máquina de conhecimento zero (ZKML), destinado a fazer a ponte entre os frameworks de IA tradicionais e a tecnologia ZK.
zkPyTorch integra profundamente as poderosas capacidades de aprendizado de máquina do PyTorch com motores de zk-SNARKs de ponta, permitindo que os desenvolvedores de IA construam aplicações de IA verificáveis em um ambiente familiar, sem mudar seus hábitos de programação ou aprender uma nova linguagem ZK completamente.
Este compilador pode traduzir automaticamente operações de modelo de alto nível (como convolução, multiplicação de matrizes, ReLU, softmax e mecanismos de atenção) em circuitos ZKP criptograficamente verificáveis. Ele combina a suíte de otimização ZKML auto-desenvolvida da Polyhedra para comprimir e acelerar inteligentemente os caminhos de inferência mainstream, garantindo tanto a correção quanto a eficiência computacional dos circuitos.
Infraestrutura chave para construir um ecossistema de IA confiável
O atual ecossistema de aprendizagem de máquina enfrenta múltiplos desafios, como a segurança dos dados, a verificabilidade computacional e a transparência dos modelos. Especialmente em indústrias críticas como a saúde, finanças e condução autónoma, os modelos de IA não só envolvem uma grande quantidade de informações pessoais sensíveis, mas também carregam propriedade intelectual de alto valor e segredos comerciais essenciais.
A Aprendizagem de Máquina de Conhecimento Zero (ZKML) emergiu como uma importante inovação para abordar este dilema. Através da tecnologia de Prova de Conhecimento Zero (ZKP), a ZKML consegue completar a verificação de integridade da inferência do modelo sem divulgar parâmetros do modelo ou dados de entrada—protegendo a privacidade enquanto garante a confiança.
Mas, na realidade, desenvolver ZKML muitas vezes tem um alto limiar, exigindo um profundo conhecimento em criptografia, que está longe do que os engenheiros de IA tradicionais podem facilmente lidar.
Esta é precisamente a missão do zkPyTorch. Ele constrói uma ponte entre o PyTorch e o motor ZKP, permitindo que os desenvolvedores construam sistemas de IA com proteção de privacidade e verificabilidade usando código familiar, sem a necessidade de reaprender linguagens criptográficas complexas.
Através do zkPyTorch, a Polyhedra Network está a baixar significativamente as barreiras técnicas do ZKML, impulsionando aplicações de IA escaláveis e confiáveis para o mainstream, e reconstruindo um novo paradigma de segurança e privacidade em IA.
fluxo de trabalho zkPyTorch

Figura 1: Visão geral da arquitetura geral do ZKPyTorch
Como mostrado na Figura 1, o zkPyTorch converte automaticamente modelos padrão do PyTorch em circuitos compatíveis com ZKP (zk-SNARKs) através de três módulos cuidadosamente projetados. Estes três módulos incluem: módulo de pré-processamento, módulo de quantização amigável ao conhecimento zero, e módulo de otimização de circuito.
Este processo não requer que os desenvolvedores dominem circuitos criptográficos ou sintaxe especializada: os desenvolvedores apenas precisam escrever modelos usando PyTorch padrão, e o zkPyTorch pode convertê-los em circuitos que podem ser reconhecidos por motores de prova de conhecimento zero, como o Expander, gerando a correspondente prova ZK.
Este design altamente modular reduz significativamente o limiar de desenvolvimento do ZKML, permitindo que os desenvolvedores de IA construam facilmente aplicações de aprendizagem de máquina eficientes, seguras e verificáveis, sem a necessidade de mudar de linguagens ou aprender criptografia.
Bloco Um: Pré-processamento de Modelo
Na primeira fase, o zkPyTorch irá converter o modelo PyTorch em um grafo de computação estruturado utilizando o formato Open Neural Network Exchange (ONNX). O ONNX é um padrão de representação intermediária adotado pela indústria que pode representar uniformemente várias operações complexas de aprendizado de máquina. Através deste passo de pré-processamento, o zkPyTorch é capaz de clarificar a estrutura do modelo e decompor o processo de computação central, colocando uma base sólida para gerar circuitos zk-SNARKs nas etapas subsequentes.
Módulo 2: Quantificação Amigável à Prova de Conhecimento Zero
O módulo de quantização é um componente chave do sistema ZKML. Modelos tradicionais de aprendizado de máquina dependem de operações de ponto flutuante, enquanto o ambiente ZKP é mais adequado para operações inteiras em campos finitos. O zkPyTorch adota um esquema de quantização inteira otimizado para campos finitos, mapeando com precisão os cálculos de ponto flutuante para cálculos inteiros, enquanto transforma operações não lineares que são desfavoráveis para ZKP (como ReLU e Softmax) em formas eficientes de tabela de consulta.
Esta estratégia não só reduz significativamente a complexidade do circuito, mas também melhora a verificabilidade e a eficiência operacional do sistema, garantindo a precisão do modelo.
Módulo 3: Otimização de Circuitos Hierárquicos
zkPyTorch adota uma estratégia de múltiplos níveis para a otimização de circuitos, incluindo especificamente:
Otimização em lote
Especificamente projetado para computação serializada, reduz significativamente a complexidade computacional e o consumo de recursos ao processar vários passos de inferência de uma só vez, tornando-se especialmente adequado para cenários de verificação de grandes modelos de linguagem, como os Transformers.
Aceleração da Operação da Linguagem Original
Ao combinar a convolução da Transformada Rápida de Fourier (FFT) com a tecnologia de tabela de consulta, a velocidade de execução de operações básicas como convolução e Softmax é efetivamente melhorada, melhorando fundamentalmente a eficiência computacional geral.
Execução de circuito paralelo
Aproveite plenamente as vantagens de poder computacional das CPUs e GPUs de múltiplos núcleos, dividindo cálculos de carga pesada, como a multiplicação de matrizes, em múltiplas subtarefas para execução paralela, melhorando significativamente a velocidade e escalabilidade da geração de Prova de conhecimento zero.
Discussão Técnica Aprofundada
Grafo Acíclico Direcionado (DAG)
zkPyTorch utiliza um Grafo Dirigido Acíclico (DAG) para gerir o fluxo computacional de aprendizagem de máquinas. A estrutura do DAG captura sistematicamente as complexas dependências do modelo, como mostrado na Figura 2, onde cada nó representa uma operação específica (como transposição de matrizes, multiplicação de matrizes, divisão e Softmax), e as arestas descrevem precisamente o fluxo de dados entre estas operações.
Esta representação clara e estruturada não só facilita imensamente o processo de depuração, mas também ajuda na otimização aprofundada do desempenho. A natureza acíclica do DAG evita dependências circulares, garantindo uma execução eficiente e controlável da ordem de computação, o que é crucial para otimizar a geração de circuitos zk-SNARKs.
Além disso, o DAG permite que o zkPyTorch lide de forma eficiente com arquiteturas de modelos complexos, como Transformers e Redes Residuais (ResNet), que frequentemente apresentam fluxos de dados complexos, não lineares e com múltiplos caminhos. O design do DAG está perfeitamente alinhado com suas necessidades computacionais, garantindo a precisão e a eficiência da inferência do modelo.

Figura 2: Um exemplo de um modelo de aprendizagem automática representado como um grafo acíclico dirigido (DAG)
Técnicas Quantitativas Avançadas
No zkPyTorch, técnicas avançadas de quantização são um passo fundamental na conversão de cálculos em ponto flutuante em operações inteiras adequadas para uma aritmética eficiente em campos finitos em sistemas de prova de conhecimento zero (ZKP). O zkPyTorch utiliza um método de quantização inteira estática, cuidadosamente projetado para equilibrar a eficiência computacional e a precisão do modelo, garantindo que a geração de provas seja rápida e precisa.
Este processo de quantização envolve uma calibração rigorosa para determinar com precisão a escala de quantização ótima para representar efetivamente números de ponto flutuante, evitando overflow e perda significativa de precisão. Para abordar os desafios únicos das operações não lineares da Prova de conhecimento zero (como Softmax e normalização de camada), o zkPyTorch transforma inovadoramente essas funções complexas em operações eficientes de consulta em tabela.
Esta estratégia não só melhora significativamente a eficiência da geração de provas, mas também assegura que os resultados das provas geradas sejam completamente consistentes com as saídas de modelos quantitativos de alta precisão, equilibrando desempenho e credibilidade, e avançando a aplicação prática de aprendizagem de máquina verificável.
Estratégia de otimização de circuitos em múltiplos níveis
zkPyTorch adota um sistema de otimização de circuito multi-camada altamente sofisticado, garantindo o desempenho máximo do raciocínio de conhecimento zero em termos de eficiência e escalabilidade a partir de múltiplas dimensões:
Otimização de Processamento em Lote
Ao agrupar várias tarefas de inferência em processamento em lote, a complexidade computacional geral é significativamente reduzida, sendo especialmente adequada para operações sequenciais em modelos de linguagem como os Transformers. Como mostrado na Figura 3, o processo de inferência tradicional de grandes modelos de linguagem (LLM) ocorre de maneira de geração token a token, enquanto a abordagem inovadora do zkPyTorch agrega todos os tokens de entrada e saída em um único processo de prompt para validação. Este método de processamento pode confirmar a correção geral da inferência do LLM de uma só vez, garantindo que cada token de saída seja consistente com a inferência padrão do LLM.
Na inferência de LLM, a correção do mecanismo de cache KV (cache de chave-valor) é fundamental para garantir a fiabilidade das saídas de inferência. Se a lógica de inferência do modelo estiver incorreta, mesmo com o cache, não será possível reproduzir resultados consistentes com o processo de decodificação padrão. O zkPyTorch garante que cada saída em zk-SNARKs tenha determinismo e completude verificáveis, ao replicar precisamente este processo.
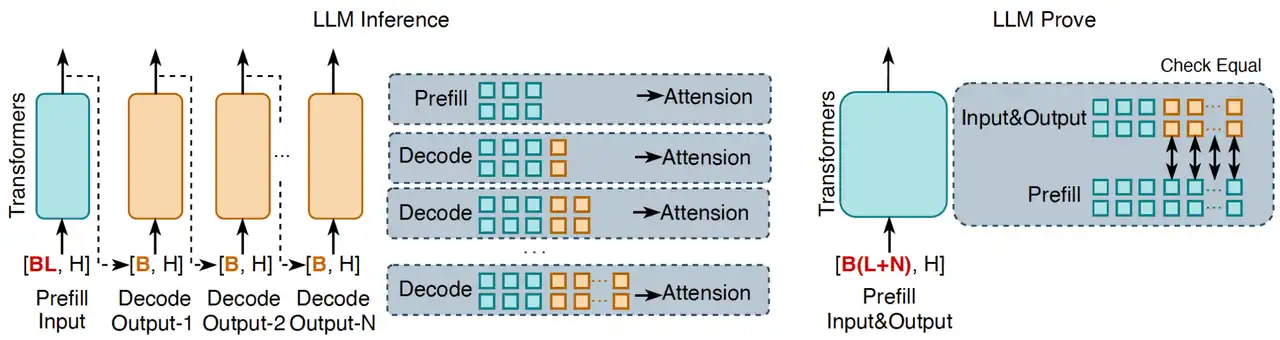
Figura 3: Verificação em lote de modelos de linguagem em larga escala (LLMs), onde L representa o comprimento da sequência de entrada, N representa o comprimento da sequência de saída e H representa a dimensão da camada oculta do modelo.
Operações Primitivas Otimizadas
zkPyTorch otimizou profundamente os primitivos de aprendizagem de máquina subjacentes, melhorando significativamente a eficiência dos circuitos. Por exemplo, operações de convolução sempre foram tarefas intensivas em computação; zkPyTorch utiliza um método de otimização baseado na Transformada Rápida de Fourier (FFT) para converter convoluções originalmente executadas no domínio espacial em operações de multiplicação no domínio da frequência, reduzindo significativamente os custos computacionais. Ao mesmo tempo, para funções não lineares como ReLU e softmax, o sistema emprega uma abordagem de tabela de consulta pré-calculada, evitando cálculos não lineares que não são amigáveis a ZKP, melhorando significativamente a eficiência operacional dos circuitos de inferência.
Execução de Circuitos Paralelos
zkPyTorch compila automaticamente operações complexas de ML em circuitos paralelos, utilizando totalmente o potencial do hardware de CPUs/GPUs multi-core para alcançar a geração de provas em larga escala. Por exemplo, ao realizar a multiplicação de tensores, zkPyTorch divide automaticamente a tarefa de computação em várias sub-tarefas independentes, que são então distribuídas para várias unidades de processamento para execução concorrente. Esta estratégia de paralelização não só melhora significativamente a capacidade de execução do circuito, mas também torna a verificação eficiente de grandes modelos uma realidade, abrindo novas dimensões para ZKML escalável.
Teste de desempenho abrangente: uma dupla quebra de desempenho e precisão
zkPyTorch demonstra um desempenho excecional e uma usabilidade prática em vários modelos de aprendizagem automática mainstream através de uma avaliação rigorosa:
Teste do modelo VGG-16
No conjunto de dados CIFAR-10, o zkPyTorch leva apenas 6,3 segundos para gerar uma prova VGG-16 para uma única imagem, e a precisão é quase indistinguível da computação tradicional em ponto flutuante. Isso marca as capacidades práticas do zkML em tarefas clássicas, como o reconhecimento de imagem.
Teste do modelo Llama-3
Para o modelo de linguagem grande Llama-3 com até 8 bilhões de parâmetros, o zkPyTorch alcança uma geração de provas eficiente de cerca de 150 segundos por token. Ainda mais impressionante, sua saída mantém uma similaridade cosseno de 99,32% em comparação com o modelo original, garantindo alta credibilidade enquanto ainda preserva a consistência semântica da saída do modelo.

Tabela 1: Desempenho de vários esquemas de Prova de conhecimento zero em redes neurais convolucionais e redes transformadoras
Uma ampla gama de cenários de aplicação no mundo real
MLaaS verificável
À medida que o valor dos modelos de aprendizagem de máquina continua a aumentar, cada vez mais desenvolvedores de IA estão optando por implantar seus modelos desenvolvidos por eles na nuvem, oferecendo serviços de MLaaS (Machine-Learning-as-a-Service). No entanto, na realidade, os usuários muitas vezes acham difícil verificar se os resultados da inferência são autênticos e confiáveis; enquanto isso, os provedores de modelos também desejam proteger ativos principais, como a estrutura e os parâmetros do modelo, para evitar roubo ou uso indevido.
zkPyTorch nasceu para resolver essa contradição: permite que os serviços de IA em nuvem tenham capacidades nativas de "prova de conhecimento zero", alcançando resultados de inferência de nível de criptografia verificáveis.
Como mostrado na Figura 4, os desenvolvedores podem integrar diretamente grandes modelos como o Llama-3 no zkPyTorch para construir um sistema MLaaS confiável com capacidades de prova de conhecimento zero. Ao integrar-se perfeitamente com o mecanismo ZKP subjacente, o zkPyTorch pode gerar automaticamente provas sem expor os detalhes do modelo, verificando se cada inferência é executada corretamente, estabelecendo assim uma verdadeira fundação de confiança interativa para os provedores de modelos e usuários.

Figura 4: Os cenários de aplicação do zkPyTorch em MLaaS verificável.
O acompanhamento seguro da avaliação de modelos
zkPyTorch fornece um mecanismo de avaliação de modelos de IA seguro e verificável, permitindo que as partes interessadas avaliem prudentemente os indicadores-chave de desempenho sem expor os detalhes do modelo. Este método de avaliação "zero leakage" estabelece um novo padrão de confiança para modelos de IA, melhorando a eficiência das transações comerciais enquanto protege os direitos de propriedade intelectual dos desenvolvedores. Ele não apenas aumenta a visibilidade do valor do modelo, mas também traz maior transparência e justiça para toda a indústria de IA.
Integração profunda com a blockchain EXPchain
zkPyTorch integra-se nativamente com a rede blockchain EXPchain, desenvolvida de forma independente pela Polyhedra Network, construindo em conjunto uma infraestrutura de IA descentralizada e confiável. Esta integração oferece um caminho altamente otimizado para chamadas de contratos inteligentes e verificação em cadeia, permitindo que os resultados de inferência de IA sejam verificados criptograficamente e armazenados permanentemente na blockchain.
Com a colaboração do zkPyTorch e da EXPchain, os desenvolvedores podem construir aplicações de IA verificáveis de ponta a ponta, desde a implementação do modelo, computação de inferência até a verificação em cadeia, realizando verdadeiramente um processo de computação de IA transparente, confiável e auditável, fornecendo suporte subjacente para a próxima geração de aplicações blockchain + IA.
Roteiro Futuro e Inovação Contínua
A Polyhedra continuará a avançar a evolução do zkPyTorch, focando nos seguintes aspectos:
Código aberto e co-construção da comunidade
Abrir gradualmente o código-fonte dos componentes principais do zkPyTorch, inspirando desenvolvedores globais a participar e promovendo a inovação colaborativa e a prosperidade ecológica no campo da prova de conhecimento zero em machine learning.
Expandir a compatibilidade de modelos e estruturas
Expanda a gama de suporte para modelos e estruturas de aprendizado de máquina mainstream, aprimorando ainda mais a adaptabilidade e versatilidade do zkPyTorch, tornando-o flexível para integrar em vários fluxos de trabalho de IA.
Ferramentas de Desenvolvimento e Construção de SDK
Lançar uma ferramenta de desenvolvimento abrangente e um kit de desenvolvimento de software (SDK) para simplificar o processo de integração e acelerar a implementação e aplicação do zkPyTorch em cenários de negócios práticos.
Conclusão
zkPyTorch é um marco importante rumo a um futuro de IA confiável. Ao integrar profundamente o maduro framework PyTorch com a tecnologia de ponta zk-SNARKs, o zkPyTorch não só melhora significativamente a segurança e a verificabilidade do aprendizado de máquina, mas também redefine os métodos de implantação e os limites de confiança das aplicações de IA.
A Polyhedra continuará a inovar no campo da "IA segura", avançando o aprendizado de máquina em direção a padrões mais elevados na proteção da privacidade, verificação de resultados e conformidade do modelo, ajudando a construir sistemas inteligentes transparentes, confiáveis e escaláveis.
Fique atento às nossas últimas atualizações e testemunhe como o zkPyTorch está a transformar o futuro da era inteligente e segura.
Declaração:
- Este artigo é reproduzido de [BLOCKBEATS] O copyright pertence ao autor original [Jiaheng Zhang] Se tiver alguma objeção à reimpressão, por favor contacte Equipe Gate LearnA equipe irá processá-lo o mais rapidamente possível, de acordo com os procedimentos relevantes.
- Aviso: As opiniões e pontos de vista expressos neste artigo são exclusivamente do autor e não constituem qualquer aconselhamento de investimento.
- As outras versões linguísticas do artigo são traduzidas pela equipe Gate Learn, a menos que indicado de outra forma.GateNessas circunstâncias, copiar, distribuir ou plagiar artigos traduzidos não é permitido.
Partilhar
Conteúdos
zkPyTorch:
Infraestrutura chave para construir um ecossistema de IA confiável
zkPyTorch Workflow
Discussão técnica aprofundada
Técnicas Quantitativas Avançadas
Estratégia de otimização de circuitos em múltiplos níveis
Teste de desempenho abrangente: uma dupla quebra de desempenho e precisão
Ampla gama de cenários de aplicação no mundo real
A escolta segura da avaliação de modelos
Integração profunda com a blockchain EXPchain
Roteiro Futuro e Inovação Contínua
Conclusão
Artigos relacionados

O que são Narrativas Cripto? Principais Narrativas para 2025 (ATUALIZADO)

Qual plataforma constrói os melhores agentes de IA? Testamos o ChatGPT, Claude, Gemini e outros

Explorando o Smart Agent Hub: Sonic SVM e seu Framework de Escalonamento HyperGrid

Como os Agentes de IA Impulsionarão a Cripto no Mercado Principal

Tudo o que precisa de saber sobre GT-Protocolo
